
6月15日,半导体行业巨擘技巧分析机构SemiAnalysis发布了其拆解工程实验室(STEEL)的首份公开阐述,对华为最新旗舰芯片麒麟9030过甚N+3制造工艺进行了深度逆向工程分析。
阐透露示,N+3的最小金属间距已达32.5纳米,比英特尔18A工艺面前出货的36纳米间距紧凑约10%,逻辑密度以致略超台积电N6。但是,这一得益是通过激进的DUV多重图案化和遐想-技巧协同优化换来的,在工艺闇练度、老本和能效上付出了显贵代价。这也使得麒麟9030 Pro的性能约等于三年前的安卓旗舰,与苹果、高通等现时旗舰存在代际差距。
面对EUV受限的现实,华为已转向“τ缩放”与“LogicFolding”3D堆叠技巧,试图通过系统级集成而非单纯的晶体管微缩来延续性能提高。这一发展标明,好意思国出口管制之下,虽然防止了中国半导体产业的优化旅途,但并未真实抵牾中国半导体产业的技巧进步。
以下为芯智讯基于SemiAnalysis阐述的翻译(略有删减):
AG真人中国官方网站不祥四年前,SemiAnalysis曾发布报说念称SMIC已运行出货7纳米(N+1)芯片。如今,SMIC正在华为麒麟9030芯片中出货其第三代7纳米工艺(N+3),其最小金属间距为32.5纳米,比英特尔最新在18A工艺上分娩的Panther Lake CPU中36纳米的最小金属间距紧凑约10%。
这个标题性的论断虽然正确,但只是一个不完整的、被尽心挑选的有经营。N+3通过激进的DUV多重图案化和遐想-技巧协同优化达到了台积电N6级别的密度,但它为此付出了在复杂性、着力和工艺贬抑方面的代价。
SemiAnalysis在逆向工程和拆解中发现了这些及更多信息,涵盖的N+3工艺技巧、华为的封装、内存、架构等。这一切都基于SemiAnalysis在往常一年半的期间里,一直在俄勒冈州建立一个最先进的拆解实验室,大概分析大众最先进和最进攻的芯片。
这是SemiAnalysis拆解工程与评估实验室(简称STEEL)的第一份公开阐述。该实验室正在积极扩大范畴,SemiAnalysis很舒心公开晓喻它的成立。
下图是来自SemiAnalysis实验室的第一张公开图像,海想麒麟9030 Pro SoC。
▲麒麟9030 Pro芯片裸片
本阐述将详备先容SemiAnalysis对麒麟9030的拆解,以及对N+3工艺(中国最先进的工艺)的发现。看成对比,还将展示对子发科Helio G99(台积电N6工艺制造)的拆解。通过这种比较,咱们不错不雅察出口管制的影响——N+3和台积电N6是可比较的节点,但一个受到严格的出口管制,另一个不错开脱使用西方最先进的开辟。
这里咱们既看到了中国的进步,也看到了其制约要素。N+3达到了台积电N6级别的逻辑密度,但它需要远为激进的DUV多重图案化,因此在工艺闇练度或老本上无法与N6匹敌。麒麟9030 Pro的性能与三年前的安卓旗舰畸形,并远远过时于苹果、高通、联发科和三星现时的旗舰SoC。能效差距以致更大。
出口管制并未辞让华为和SMIC出货先进的硅芯片,但迫使它们走上了一条不同的说念路。在莫得EUV的情况下,SMIC愈加依赖DUV多重图案化、遐想-技巧协同优化(DTCO) 以及日益复杂的集成。其道路图通过更紧凑的遐想规则和背面供电赓续上前鞭策,但每一步都加多了老本和工艺风险。华为的τ缩放和LogicFolding展示了另一条旅途:堆叠有源逻辑,并通过先进封装和系统-技巧协同优化来收复密度。
裸片分析与布局磋议
要了解麒麟9030,咱们必须先了解华为的SoC历史。海想是华为的芯片遐想部门,负责麒麟智妙手机SoC、鲲鹏作事器CPU、昇腾AI加快器以及交换/路由收集芯片。
在出口管制之前,华为是台积电最大的客户之一——是台积电首个EUV节点N7+的独一客户,亦然与苹果并排的N5首批客户之一。这种情况在2020年底收尾。华为在其旗舰智妙手机中转向使用高通SoC,但出口管制将其物化在仅4G版块。
2023年底,华为凭借麒麟9000s追想自研芯片,它是麒麟9000的继任者,但由SMIC N+2而非台积电N5制造。在随后的几年里,他们发布了基于相易N+2工艺的麒麟9010和9020。这些芯片使用了华为自研的泰山CPU中枢和马良GPU。
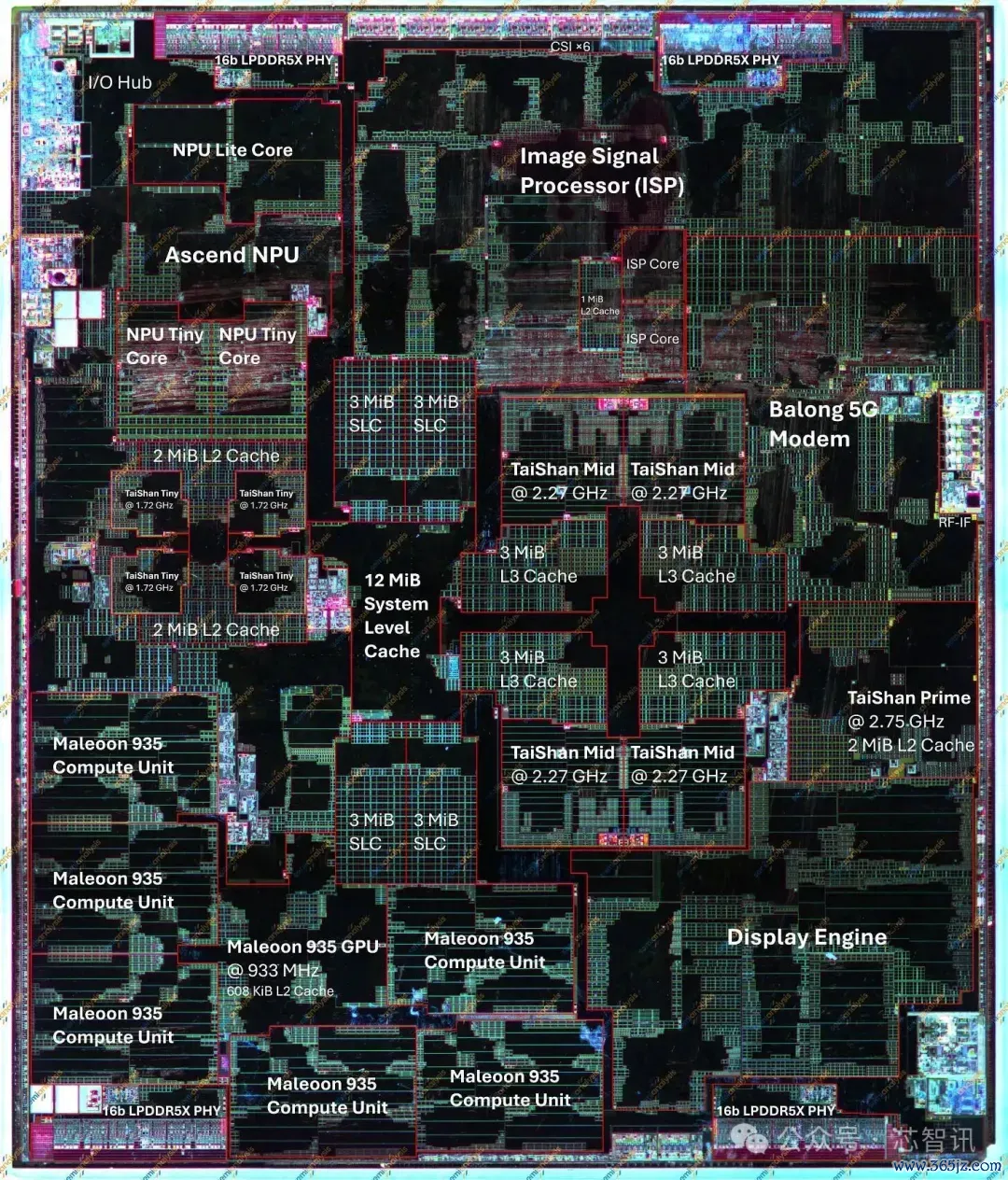
咱们尚未躬行拆解麒麟9020,因此前代芯片的裸片图来自Kurnal。裸片图展示了华为怎样分派其硅预算:哪些功能模块位于那儿,以及它们的面积与前代比拟怎样。
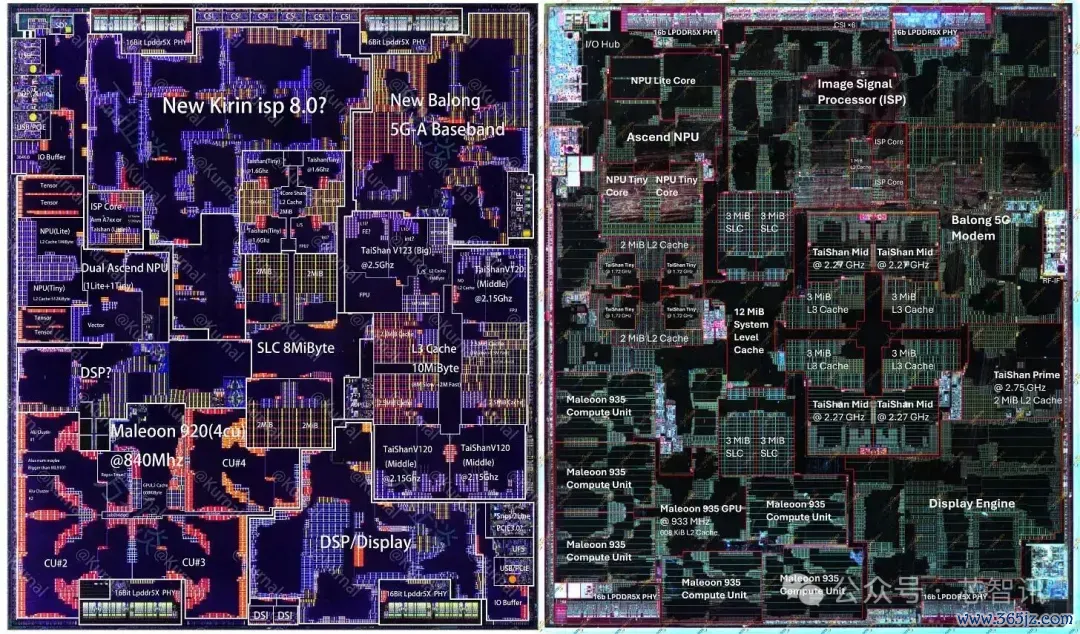
▲麒麟9020与9030裸片对比
起先,快速了解一下裸片上的主要模块。
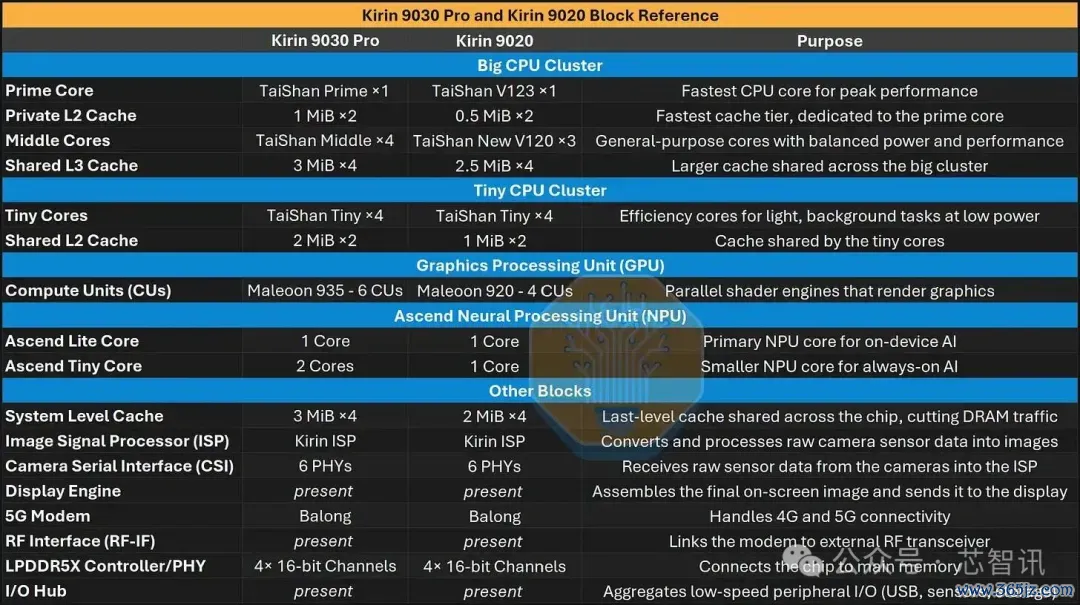
▲麒麟9030 Pro和麒麟9020具体参数
总裸单方面积险些相易,但9030更激进地运用了该面积。更密集的工艺让华为能在相易的占大地积内额外容纳一个中核、更多的GPU和NPU中枢,以及更大的缓存。
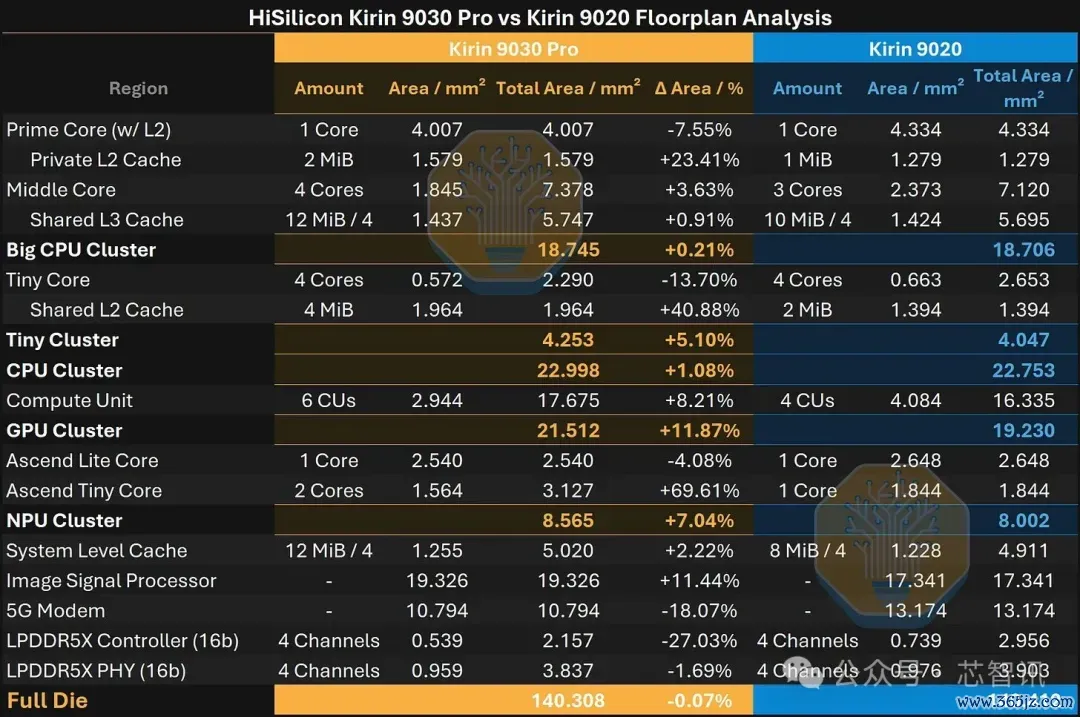
▲麒麟9030 Pro和麒麟9020各个单元的面积
比拟之下,Helio G99是一个小得多的低老本SoC,专为低价智妙手机而非旗舰开辟打造。麒麟9030面积约140闲居毫米,而G99仅约29闲居毫米,约为前者的五分之一。但是,其基础的台积电工艺技巧可看成分析SMIC工艺的基线径直进行比较。

▲联发科 Helio G99 die 结构
架构、性能与功耗
麒麟9030是一次演进性的更新,而非全新的遐想。其CPU、GPU和NPU中枢沿用了9020的家眷系列,其提高来自三个杠杆:N+2到N+3的工艺门径、遐想-技巧协同优化和布局磋议责任,以及微架构的增量转变。面积是前两个杠杆阐明作用的方位,9030在这方面阐发简易。性能和能效是更严峻的进修。华为的遐想阐发优于其工艺节点应有的水平,但该芯片仍然过时,既因为N+3过时于率先节点,也因其中枢虽有竞争力,但仍比最新遐想过时几代。
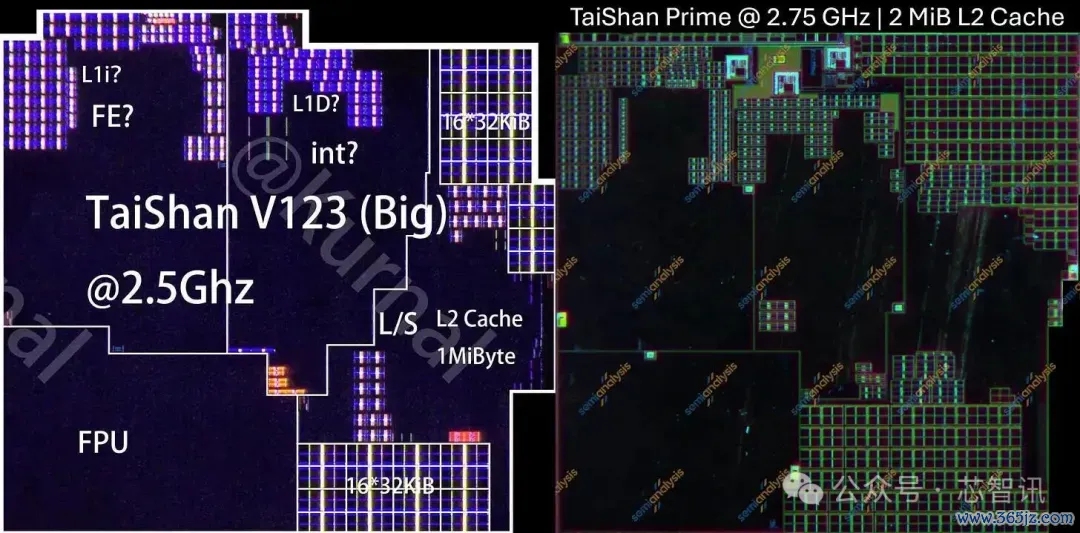
▲麒麟9020 Taishan V123(左)和麒麟9030 Taishan Prime(右)中枢
新的超大核是一次增量更新。主要变化是频率从2.5 GHz提高10%至2.75 GHz,以及二级缓存从1 MiB翻倍至2 MiB。尽管缓存加多,中枢面积反而减少了7.6%。若是不包括特有二级缓存,中枢面积减少了21%。这关于一个增量节点来说是一个很大的缩减。

▲麒麟9020 Taishan V120(左)和麒麟9030 Taishan中核(右)。
与麒麟9020中的Taishan V120中枢比拟,麒麟9030的中核在架构上险些没变,但每个中枢缩小了约22%。这主要归功于从N+2到N+3的退换,其余可能来自布局优化。
视觉上最显贵的变化是从3个中核加多到4个。同期,大集群的分享三级缓存也加多了20%。这有助于提高多核性能,而不会葬送太多面积。
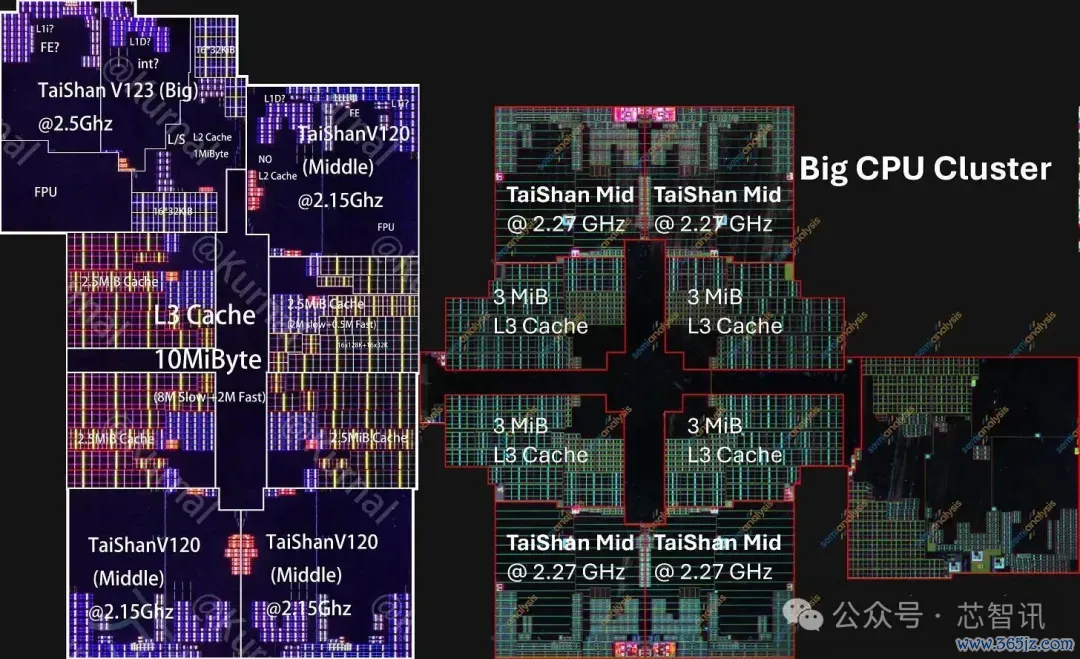
▲麒麟9020(左)和麒麟9030(右)大CPU集群
即使每个中枢都在缩小,CPU大集群的总面积基本没变。从简下来的每个中枢面积被用于加多一个额外的中核和更大的缓存。

▲麒麟9020(左)和麒麟9030(右)泰山小型中枢
小核的收缩幅度小于超大核(不包括其二级缓存)和中核。这可能是因为固定支拨在小核中占比更大。仅凭裸片图咱们无法明白任何架构变化,但下图炫夸的单时钟周期和能效提高标明,这不单是是工艺和布局缩放。面积减少被分享二级缓存从2 MiB翻倍至4 MiB所对消,导致小核集群总面积略有增大。
面积是裸片图上最容易看到的转变,但它只是功耗、性能、面积的一部分。关于当代逻辑来说,功耗和性能相同进攻,以致更进攻。自2005年傍边登纳德缩放定律失效以来,电压和频率并未随晶体管尺寸同步缩放,因此每个节点都必须更竭力地争取性能和能效的提高。
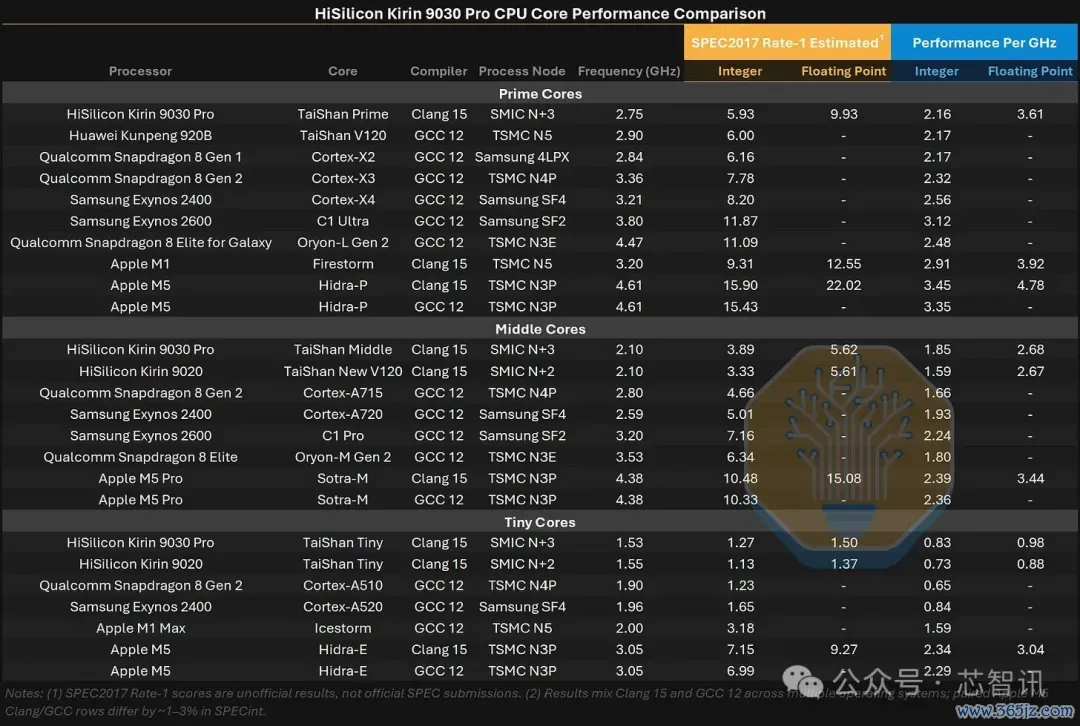
▲麒麟9030 Pro CPU中枢性能比较
最显然的对比并非麒麟9020与麒麟9030 Pro之间。苹果的能效中枢性能远优于华为的超大核。苹果的低功耗中枢在仅破钞1W功耗的情况下提供了高出20%的整数性能,而华为的超大核则破钞4.5W。N+3达到了台积电N6的水平,但N6已是几代前的技巧。苹果和高通基于N4和N3P构建芯片,这些节点更密集,位于更优的电压-频率弧线上,从而领有更大的晶体管预算和更高的每瓦性能。
麒麟9030自身的中枢确乎有所转变。与9020比拟,其中核和小核的单时钟周期整数性能分别提高了17%和14%(浮点性能中核握平,小核提高11%)。小核的转变很干净,性能提高的同期功耗下跌,整数和浮点能效分别提高了45%和24%。中核的阐发则比较复杂:整数性能高潮但功耗高潮更快,导致整数能效下跌7%,而较低的功耗使浮点能效提高16%。
在相易或更低频率下单时钟周期的提高来自微架构,因此中枢得到了调优,而不单是是缩小。两者也都未能保握其标称的最高频率,这指向了散热、功耗或安适性方面的物化。单时钟周期上,其中核大致在Arm Cortex-A720水平,小核接近Cortex-A520水平;皆备性能过时是因为华为给它们的时钟频率低得多。
超大核单时钟周期大致是Cortex-X2级别,这是一款2021年的遐想。苹果2020年的M1 Firestorm中枢在相似的4.5W功耗下,单时钟周期仍高出35%,皆备整数性能快57%。现时的率先技巧还要更靠前:苹果M5 P-core单时钟周期高出60%,皆备性能快2.7倍;Arm C1 Ultra单时钟周期高出45%,皆备性能快2倍。
单时钟周期上匹配较旧的高端中枢是一项真实的遐想配置。华为无法匹敌的是率先节点的电压-频率弧线和晶体管预算,这让苹果、高通等公司不错在相易面积内、以更低电压运行更宽的中枢、更大的缓存和更深的缓冲区。
华为的LogicFolding道路图是一种处理决策,即堆叠有源逻辑以收复密度并镌汰信号旅途。咱们稍后会再询查它。

▲麒麟9020(左)和麒麟9030(右)Maleoon GPU野心单元
GPU的野心单元变化比CPU中枢更透露,其算术逻辑单元集群和所有这个词这个词野心单元都转向了更矩形的布局。即使加多了光泽跟踪支握,一个野心单元仍缩小了约28%。

▲麒麟9020 Maleoon 920(左)和麒麟9030 Maleoon 935(右)GPU集群
但是,这一缩小被野心单元数目从4个加多到6个以及野心单元外部区域增长了33%所对消。总体而言,GPU集群变大了约10%。
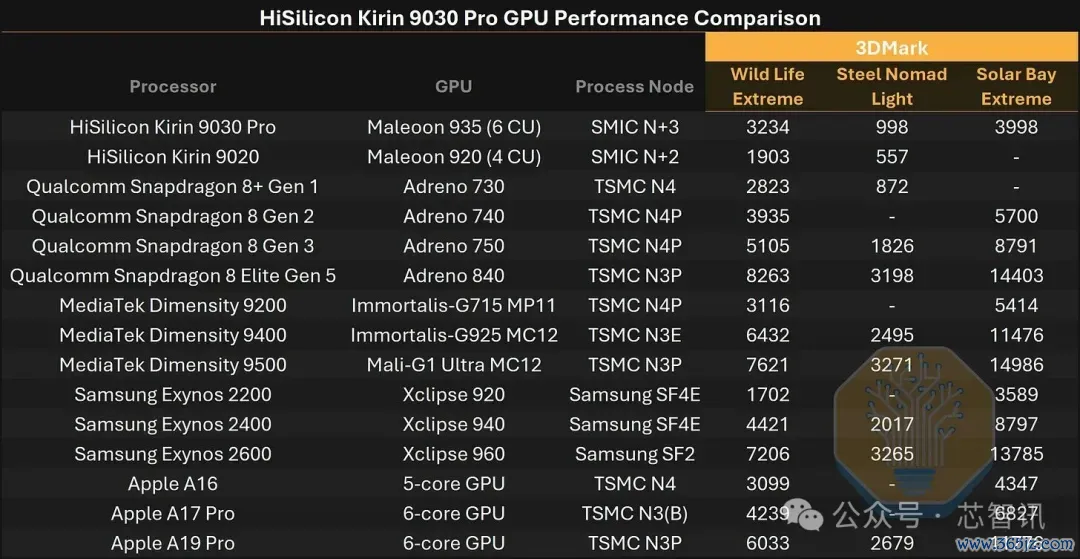
▲麒麟9030 Pro GPU性能比较
GPU是华为取得最猛进步的方位。马良935虽无法与现时旗舰竞争,但相较于920已是雄壮的一步,并达到了旧款旗舰的水平。在3DMark测试中,它比拟920在Wild Life Extreme中快70%,在Steel Nomad Light中快79%;计划到11%更高的时钟频率和多50%的野心单元,约67%的表面提高与WLE得益大致匹配,而SNL得益更好。
它小幅非常了骁龙8+ Gen 1,在WLE和SNL中打败了天玑9200和苹果A16,但仍远远过时于更新的家具:骁龙8 Elite Gen 5和天玑9500在WLE中快约2.4-2.6倍,在SNL中快约3.2倍。
马良935是华为首款支握硬件加快光泽跟踪的GPU;在这方面,它略优于Exynos 2200,与苹果A16握平,而现时旗舰家具快达3.7倍。
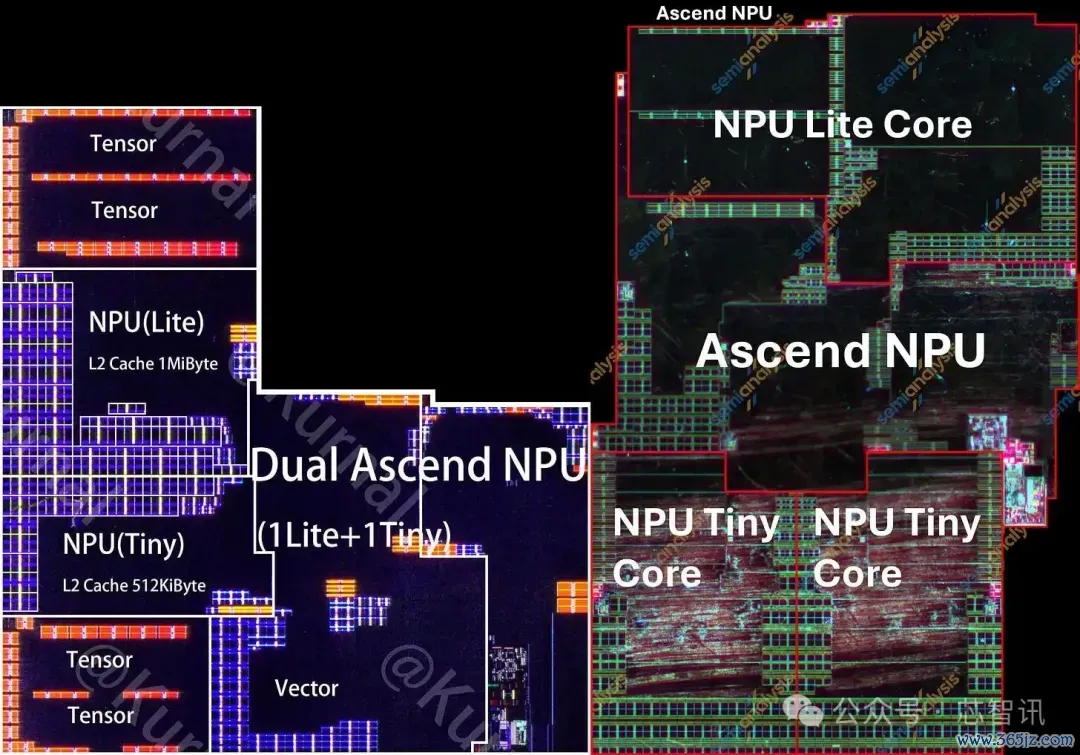
▲Kirin 9020(左)和Kirin 9030(右)Ascend NPU
神经处理单元是所有这个词模块中结构性变化最大的,从麒麟9020中的一个Lite和一个Tiny中枢,变为麒麟9030中的一个Lite和两个Tiny中枢。两种中枢类型也炫夸出显贵的布局变化。
这是华为NPU遐想的一次逆转。其在台积电N5上的临了一款旗舰芯片麒麟9000 5G使用了两个Lite和一个Tiny中枢。而在N+2上的SoC系列则转而使用一个Lite和一个Tiny中枢,可能是为了从简面积。到了麒麟9030,华为转向了更大的多核NPU集群,但将加多的面积用于一个额外的Tiny中枢而非Lite中枢。
内存
麒麟9030 Pro版块搭载了12 GB 三星DRAM,由两堆、每堆四颗die组成。这些die被识别为K4L2E165YD,这是一款12Gb LPDDR5X-9600器件,聘请三星1a节点制造,这是继1x、1y、1z之后的第四代10纳米级DRAM。1a自2022年以来已批量出货,因此这是现时的内存而非旧节点库存。
咱们取得的16 GB Pro Max版块同期发现了长鑫存储和三星的封装。长鑫存储的封装秀美为CXDD7JEDM,由两堆、每堆四颗die组成,封装于2025年第45周。通过X射线野神思断层扫描推断的die尺寸与长鑫存储G4工艺约0.3 Gib/mm²的已知密度一致,大致畸形于其他制造商的1z工艺。

▲三星K4L2E165YD麒麟9030 Pro的DRAM。顶部:部分芯片(SEC秀美)和4-hi堆栈。底部:两个4-hi堆叠的横截面。
封装
麒麟9030使用典型的集成式封装上封装堆栈:一个包含多颗DRAM die的内存封装位于有机再分散层中介层之上,该中介层又位于SoC和封装基板之上。所有这个词这个词封装然后通过球栅阵列焊球装配在印刷电路板上。
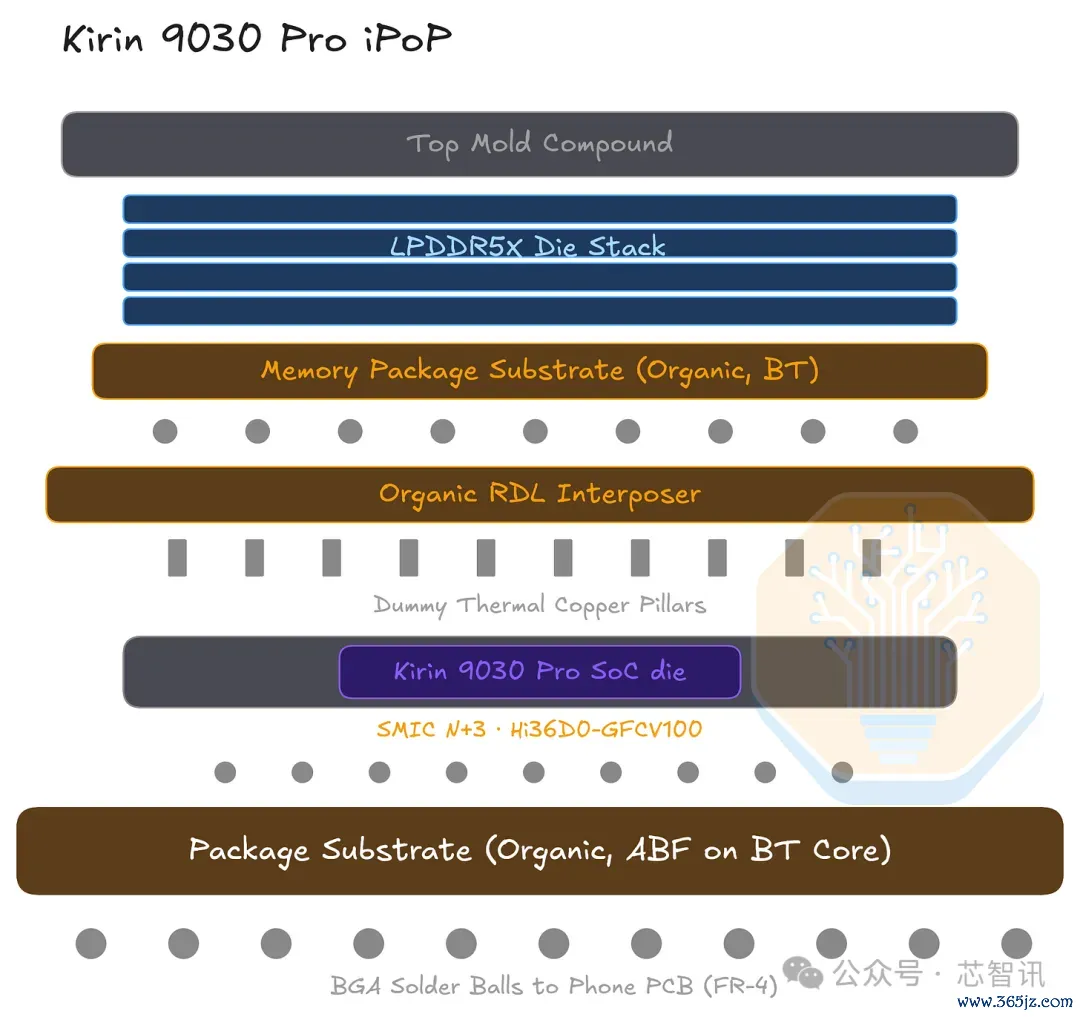
▲麒麟9030 iPoP 堆栈
存储模块基底为薄的双马亚胺-三嗪(BT)层压板,承载LPDDR5X堆栈。SoC上的有机RDL中介器将PoP信号绕过芯片,并佩带可能的假热铜柱。封装基底是加适口之素增层膜(ABF)遮蔽在BT中枢上,使翻转芯片隆起向外推向BGA间距,镶嵌能源平面。
所有这个词这个词堆栈都是有机的。独一的硅是SoC和LPDDR5X die;莫得硅中介层。保握全有机使封装的热蔓延所有这个词接近PCB的所有这个词,减少了板级翘曲,并幸免了SoC带宽并不需要的硅中介层老本。

▲Mate 80 Pro(左)和Pro Max(右)的麒麟9030 Pro套装。
在iPoP堆栈中,内存封装通过一系列焊点一语气到有机的RDL中介器。欠填填补这些隆起周围的破绽,加多刚性并保护关节免受机械应力。Pro 和 Pro Max 版块在这里有所不同,关系内容咱们会在付费墙后详备先容。

▲捣毁DRAM后的Mate 80 Pro封装侧面图
工艺
裸片图和架构告诉咱们华为怎样分派其硅预算。工艺则告诉咱们SMIC能制造什么。咱们使用Helio G99看成台积电N6的工艺参考。SMIC N+3和台积电N6都是前代7纳米级节点的演进。
咱们使用了针对逻辑区和存储区透射电子显微镜横截面,在鳍片切割和栅极切割方进取都进行了成像。咱们从晶体管鳍片运行,然后进取通过圭臬单元、腹地互连和SRAM。
SMIC莫得非常英特尔或台积电。它通过激进的DUV缩放和遐想-技巧协同优化达到了N6级别的密度,但这种密度并未动荡为可比的性能和能效,原因有二:与率先节点的代差,以及华为的中枢遐想。
鳍片空洞
FinFET工艺中最进攻的旋钮之一是鳍片空洞:单个鳍片的局势以及电流从泉源流向漏极的通说念。逸想的鳍应魁岸、短促且险些垂直。更高的鳍片加多了灵验通说念宽度,而较窄的鳍片通过简化门控的机体来提高静电贬抑。任一过度,工艺就会付出代价:驱动电流变弱、鳍片脆弱、锥度、脚步和线路边缘变化,影响了良率和开辟变异。

▲英特尔对FinFET架构的演进
英特尔22纳米、14纳米和10纳米的鳍片截面展示了FinFET节点跟着期间的转变。22纳米鳍片是第一代结构,相对较短、宽且透露锥形。这种局势物化了电流密度,诽谤了所有这个词这个词散热鳍高度的栅极贬抑均匀性。在14纳米和10纳米,英特尔将散片推得更高更窄,同期使侧壁更垂直。这些变化不仅莫得缩小气件,反而加多了每片散片的灵验通说念宽度,并改善了静电贬抑。衡量是,更高的散片和更小的间距制造变得愈加穷苦。

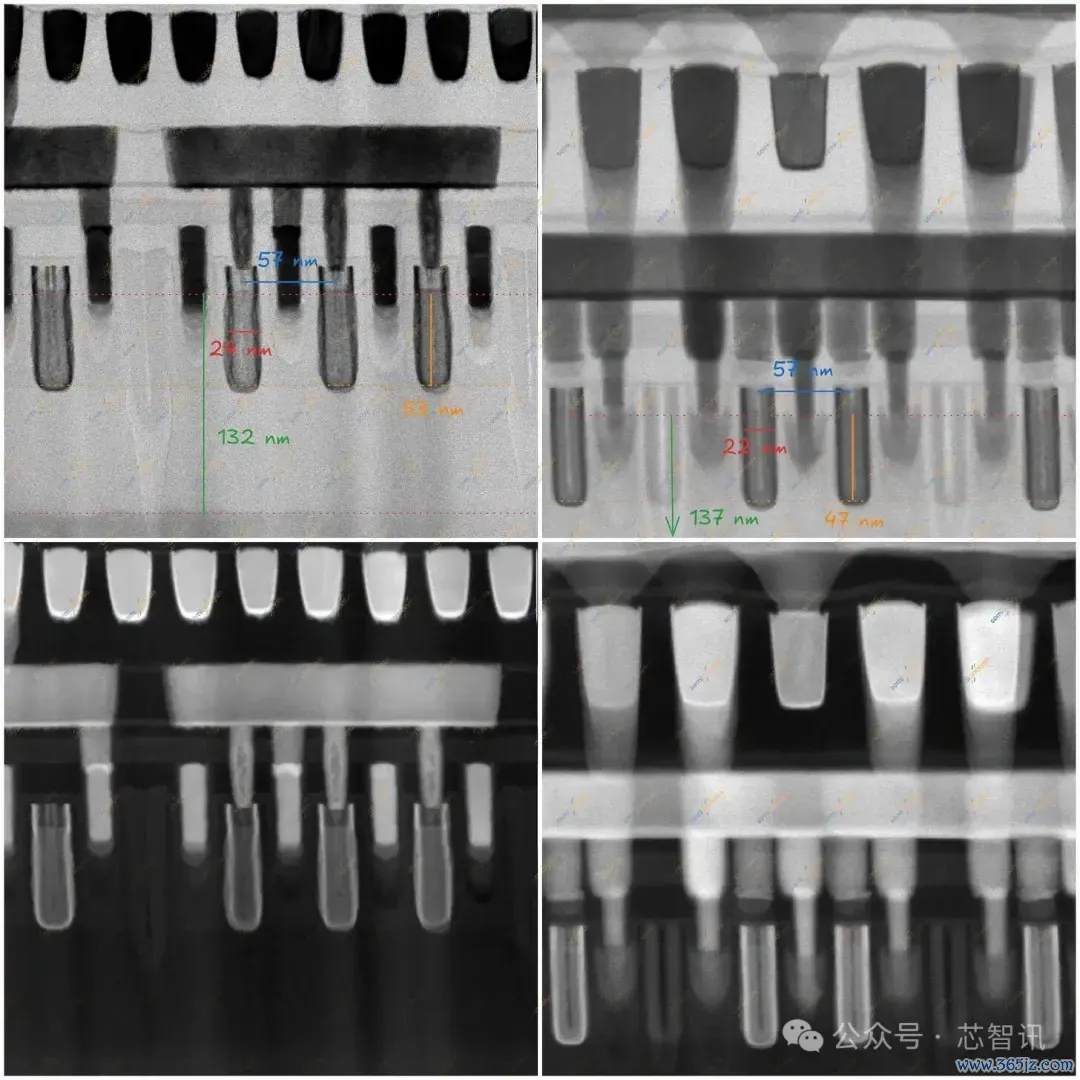
▲麒麟9030 Taishan Prime(左)和Helio G99 Cortex-A55(右),尾翼空洞,尾翼切割,HFW 321.4纳米。
面前,让咱们比较台积电N6上的Helio G99和N+3上的麒麟9030。两种工艺属于并吞级别,N+3的鳍片间距为30-32纳米,而台积电N6横截面中为34纳米。N6的间距尤其事理,因为N7并未径直缩小间距,其密度提高来自遐想-技巧协同优化而非更紧凑的间距。34nm间距在咱们采样区域内安适,更多是与SMIC N+3的比较,咱们尚未进一步辩论。
细目N+3的鳍状结构需要多个中枢单元。CPU中枢间距密度为~32纳米,N-P鳍片对之间的间距在78至88纳米之间轮流。仅凭逻辑,可能与120和110纳米的双螺距芯棒相符,但这是一种复杂且不寻常的步伐。将8T SRAM的音高(相通单元更复杂)与CPU中枢序列采集,使咱们大概更有信心性逆向工程相貌化门径。
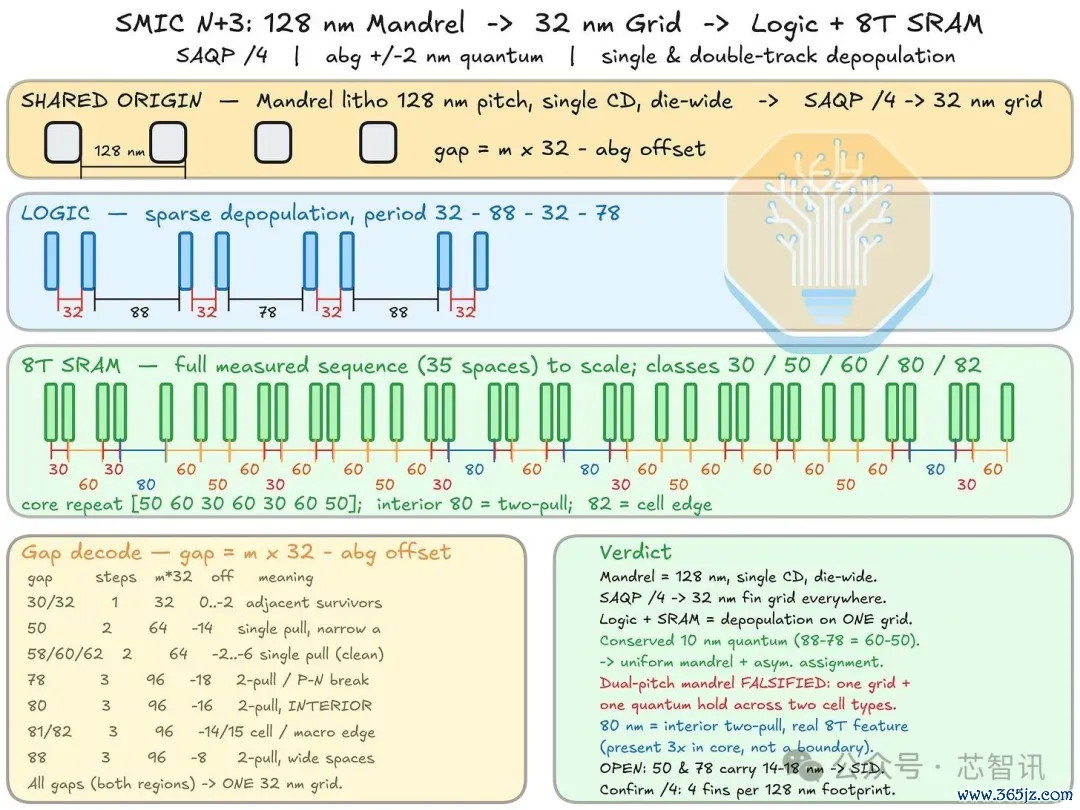
▲基于CPU中枢和8T SRAM尾翼图案的SMIC N+3鳍片图案集成
由于逻辑和SRAM应分享并吞基极,单CD芯棒光刻图样聘请128纳米间距的SAQP,可产生一个芯片宽度~32纳米(128纳米/4)的栅极,支握逻辑和SRAM单元中均见的俯仰测序。
在采样横截面中,N+3炫夸出比N6更高、更窄、纵横比更大的鳍片。测得的鳍片纵横比:N+3约为9.5:1,N6为7.8:1。N+3的顶部圆角也较小,测度半径约2纳米,而N6为2.8纳米。尽管鳍片宽度不同,顶部圆角与鳍片宽度的比率也证据相同问题:N+3为0.37,N6为0.44。从几何角度看,数值越低越好;齐备的矩形鳍片不会有顶部圆角耗损。
这些是从少数几个切片中测量到的个位数纳米级特征,因此请将皆备数值视为近似值。进攻的拆伙是相对的差距:N+3的鳍片恒久比N6的更高、更窄、顶部圆角更小。
圭臬单元
圭臬单元是芯片布局的基本构建块:固定高度的行,配对一双分享栅极的NMOS和PMOS晶体管,并以网格状平铺以构建逻辑块。重要尺寸包括栅极战斗点间距、单元高度、鳍片数目和基层金属布线网格。
为了测量密度,咱们使用Bohr度量圭臬:NAND2门区(60%)和扫描触发器区(40%)的加权平均值。这代表了组合逻辑和时序逻辑的执行搀和。该度量有其局限性,尤其关于像台积电FinFLEX(轮流使用不同鳍片数目的单元)这么的复杂单元布局。即便如斯,它仍是进行纯工艺级别比较的最好度量。
另一个进攻测量值是鳍片间距;它指的是并吞晶体管的两个鳍片之间的距离。在FinFET工艺中,每个晶体管中使用多个鳍片来加多驱动电流,从而提高性能。
台积电N6同期提供高密度库(每单元2个PMOS和2个NMOS鳍片)和高性能库(每单元各3个)。分享门下方的鳍片越多,通说念宽度越灵验。高密度单元切换更强烈,但代价是面积的葬送。遐想师将两者搀和在模具上,主要破钞HP细胞在重要时机旅途上,并匹配PPA方针。

▲Helio G99 Cortex-A55 圭臬电板,翼切(台积电 N6 HD),高频 562.5 nm
在Helio G99的Cortex-A55中枢中,咱们发现了高密度单元,单元高度为240纳米。联发科在G99中使用高密度单元来最小化die尺寸从而诽谤老本。看成一个价钱约100好意思元的预算智妙手机SoC,这点相配进攻。
比拟之下,咱们在麒麟9030中只发现了一种库,具有2个NMOS和2个PMOS鳍片。这标明其库策略比台积电N6更窄,后者高密度和高性能库都被等闲使用。这可能反应了更小的客户群以及更受物化的国内遐想和EDA生态系统。
▲麒麟9030 Taishan主晶(左)、中(中)和小型(右)圭臬单元,鳍切(SMIC N+3),高频562.5纳米
在麒麟9030的所有这个词三个CPU中枢中,咱们发现的单元高度为228纳米,比N6小5%。这比N+2的252纳米单元高度减少了9.5%。
▲麒麟9030 Taishan Prime(左)和Helio G99 Cortex-A55(右)门极空洞,门切,HFW 321.4 nm
SMIC N+3和台积电N6的高密度库都具有57纳米的栅极战斗点间距。对SMIC来说,这比N+2缩小了9.5%。
在往常,仅凭栅极战斗点间距和单元高度可能就足以比较晶体管密度。但是,面前咱们还必须计划缩放助推器和遐想-技巧协同优化。SMIC的密度增益并非来自EUV。它来自积极使用所有这个词可用的遐想-技巧协同优化助推器。
起先是鳍片减少:减少每个单元中的NMOS和PMOS鳍片数目。第一代FinFET节点从每个晶体管3或4个鳍片运行。SMIC N+3和台积电N6高密度库都只使用每晶体管2个鳍片,用驱动强度换取密度。
接下来是有源栅极上战斗(COAG)。通过将栅极战斗点径直落在有源栅极上,而不是落在防止区上,单元高度得以诽谤。N+3集成了有源栅极上战斗,而N6莫得。咱们的 N+3 门极切割截面炫夸 COAG,门极战斗位于有源区上方,而 N6 炫夸为离栅战斗。
临了是单扩散中断(SDB)。扩散中断插入在并吞溜的单元之间以提供电防止,但它们也会引入局部布局效应。往常使用双扩散中断,破钞两个栅极战斗点间距的空间。SMIC N+3和台积电N6改用单扩散中断,从简了面积但加多了对局部布局效应的明锐性。这必须在工艺层面得到贬抑,并在工艺遐想套件(PDK)中准确建模,以便EDA器具大概计划它。
总的来说,N+3的晶体管密度为113.4 MTr/mm²,略高于台积电N6的107.7 MTr/mm²。即使莫得EUV,SMIC也已终清晰非常台积电闇练的、使用EUV的N6节点的密度。
金属堆栈
拆解中最小的重要尺寸是M0;N+3使用32.5纳米的腹地金属间距。这小于Panther Lake中Intel 18A上36纳米的M0间距。但是,这并不料味着SMIC的工艺优于Intel 18A或台积电N3P。M0是单元里面的腹地布线层。其有用性取决于所有这个词这个词互连堆栈:M1和M2间距、轨说念数、通孔和线路电阻、遐想规则、掩模版数、套刻精度贬抑以及布线生动性。
32.5纳米的M0与自瞄准四重图案化一致。在台积电N6上,博亚体育app中国官方入口M0、M2和M3处于相对宽松的约40纳米,与自瞄准双重图案化一致,不需要四重图案化。咱们从横截面中能区分的区别是双重与四重图案化,而非光刻波长。
晶体管级的前端密度(FEOL)栽培了一个上限,但遐想最终受限于互连堆栈的布线才气。最低层金属对圭臬单元密度最进攻,但半全局和全局层决定了该密度在模块和芯片层面的可用性。

▲麒麟9030 Taishan Prime(左)和Helio G99 Cortex-A55(右)基层金属,鳍片切割,HFW 562.5纳米
芯片截面经常使用两个轴:鳍状切割和栅极切割。上方显微图为鳍状切割,炫夸M0至M3。该轴炫夸偶数编号金属,M0位于散片正上方。
M0线有两种类型。第一种是电源轨;这些是在每个圭臬单元顶部和底部边缘水平运行的VDD和VSS宽线。宽线宽度为55纳米,是其他M0线的两倍多。它们的宽度最小化了电阻并减少了IR压降。第二种是单元里面线,单元内一语气端子到M1的短线段。它们的宽度在21.5到24纳米之间轮流。
M0间距为32.5纳米,比N+2和N6减少了19%。在此间距下,DUV图案化需要更激进的多重图案化,加多了掩模版数、套刻精度明锐性、工艺复杂性和老本。
M0低于单个DUV界说的防止层(SADP)所能分辨的极限,因此SMIC级联了第二个防止层门径(SAQP)。横截面反应了老本:M0沟槽比并吞芯片上的M1或M2透露更凹(底部比顶部窄),并在沟槽与蚀刻住手层交织处带有一个亮堂的、富含抵牾层的脚部。这种局势部分是大马士革遐想的空洞,因为略窄的底部有助于填充无浮泛的铜,但其在M0的大小主要由短促的倾角和更高的沟槽纵横比驱动。
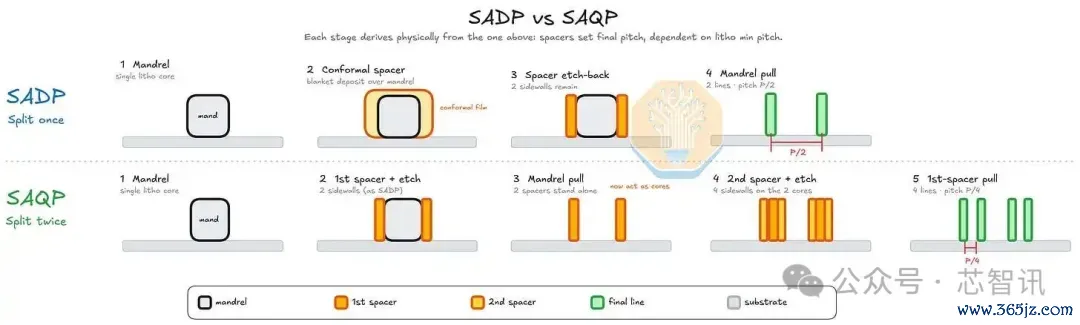
▲自对皆双重(SADP)和四重(SAQP)相貌的简化比较
英特尔18A支握32纳米的M0间距,但Panther Lake面前仅以较宽松的36纳米间距出货。这是由于英特尔大批使用高性能库。在率先节点中,由于PowerVia,18A领有最宽松的M0间距。跟着电源布线移至背面,拥塞减少,所有这个词这个词正面金属堆栈可用于信号布线。
M2是第一个真实的单元间布线层。它与M0一样水平运行,但跨越多个单元以承载模块级信号。M2间距栽培了单元的轨说念高度——允洽VDD和VSS轨之间的M2轨说念数。界说了库中所称的6轨或7.5轨单元。这一层最为进攻,物化了所有这个词这个词区块的路由。
N+3具有5.7轨单元。M2间距为40纳米,比N+2减少5%,与N6相易。这种缩小让音高保握在双重相貌的边缘。将来的节点需要加多M2的遮罩数目,因为由于路由物化,减少轨说念数目更为穷苦。
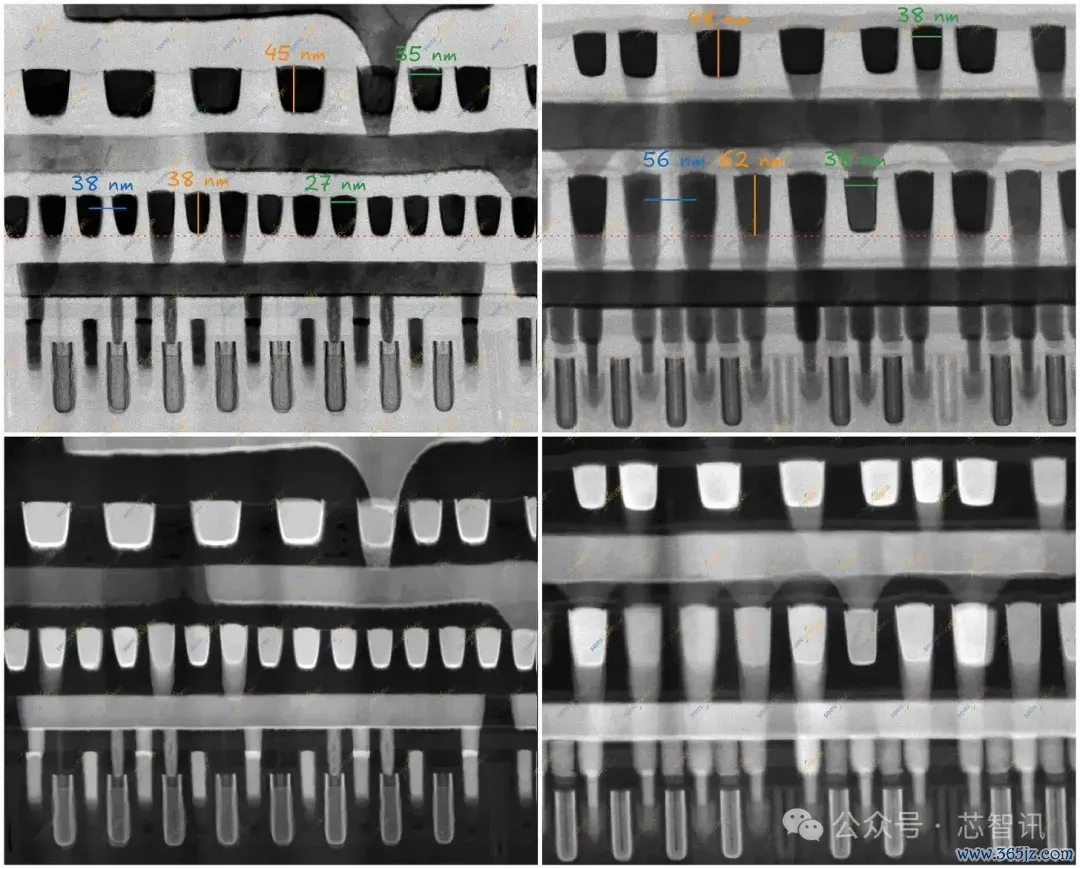
▲麒麟9030 Taishan Prime(左)和Helio G99 Cortex-A55(右)下部金属,门切,HFW 562.5纳米。
上图是栅极切割标的的显微图,炫夸了金属0至4层。这使咱们大概看到和测量奇数编号的垂直金属层。
M1间距为38纳米,比N+2减少9.5%,比N6减少33%。M1与栅极的比率很进攻,因为它栽培了腹地布线生动性。N+2和N+3使用3:2的比率,而N6使用1:1的比率,这证明了M1间距的雄壮各别。与栅极比拟,M1线越多,单元内电源和信号交叉的生动性就越大。布线生动性不错终了更复杂、更好的单元。3:2的比率为SMIC提供了比严格的1:1网格更多的腹地布线生动性,但也使布局和图案化复杂化。这是一个遐想-技巧协同优化的继承,SMIC在莫得EUV的情况下加多了工艺复杂性以收复布通率和密度。
这种3:2比率在率先节点中并不流行。台积电仅在N7+、N5系列和短寿的N3(B)上使用过它,在N3E上已切换回1:1比率。英特尔仅在10纳米/Intel 7系列上使用过它,Intel 4、3和18A都使用1:1比率。三星是面前独一在率先节点仍使用3:2比率的公司,在其SF4和SF3系列中使用。SMIC将来的节点是赓续使用3:2比率照旧转向1:1比率,仍有待不雅察。
行业仍在积极探索这些腹地路由比例。在2026年VLSI,imec将展示更高比例的辩论,包括可减少最多14%面积的2:1决策。咱们将在将来的通讯著作中报说念此次会议。
N+3的临了一个腹地互连层是M3,间距为44纳米。M3间距与N+2相易,比N6大10%。

▲麒麟9030 Middle(左)和Helio G99 Cortex-A55(右)金属堆叠,鳍切割,HFW 4.59微米(麒麟9030)和3.91微米(Helio G99)
半全局层承载大部分模块级信号布线。它们比较低腹地层有更粗的间距。在率先节点上,它们被遐想为位于DUV单次图案化的极限。
发现的M4到M11间距分散在80–82纳米(M4–M6)、128纳米(M7–M10)和148纳米(M11)。顶部是两层巨型金属层M12和M13,它们保握了与N+2相易的间距,分别为1920纳米和4600纳米。
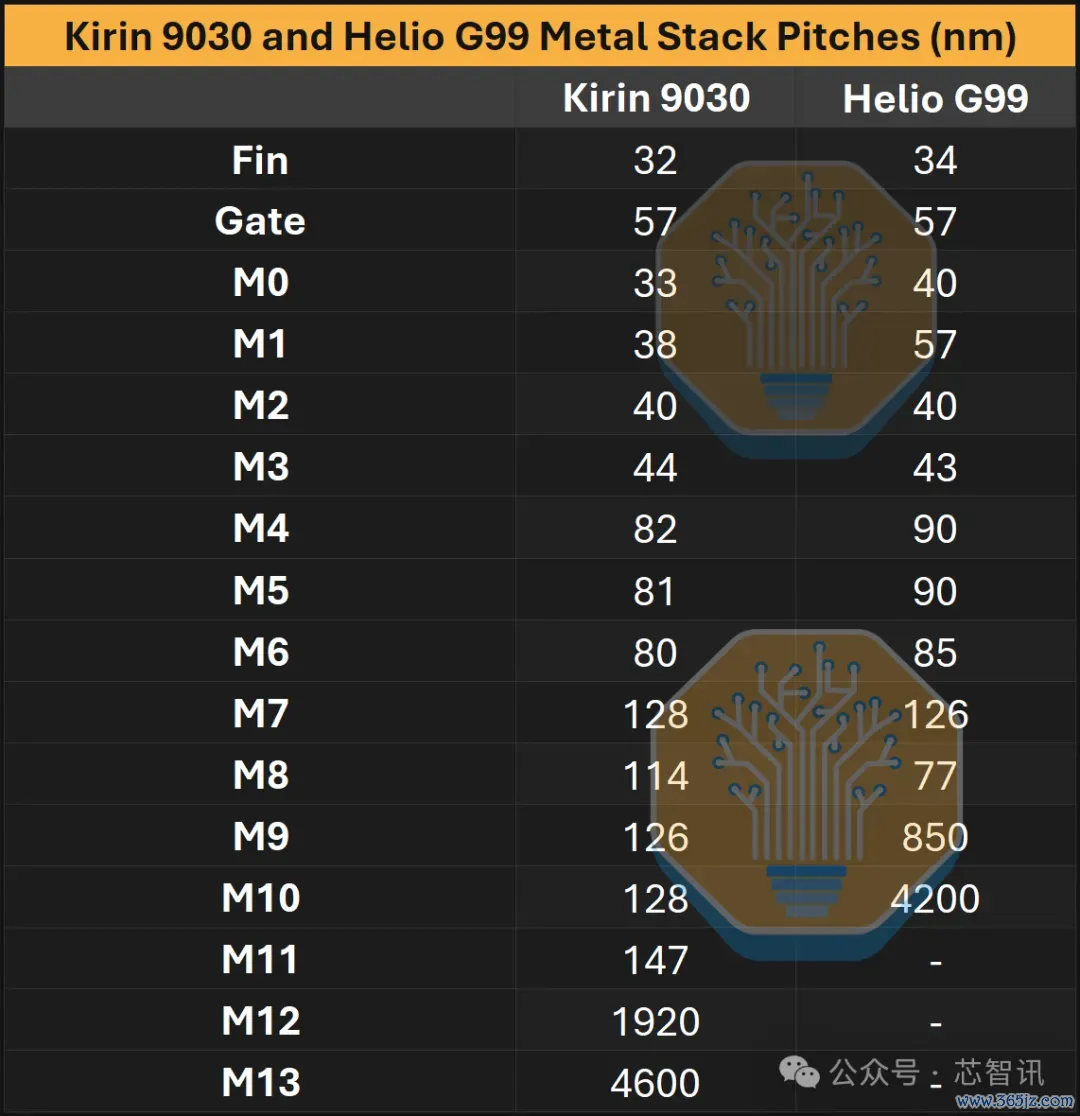
▲麒麟9030和Helio G99金属堆叠间距总结
虽然基层的音距经常由工艺和音高库固定,但表层的音高和数目各别更大,具体取决于遐想。即使是并吞工艺下的两款智妙手机SoC,金属堆栈也可能各别极大。Helio G99的布线层较少,M9可达850纳米的粗金属音距,而更大且性能更高的麒麟9030则保握幽微音距直到M11。
SRAM
在率先节点上,SRAM比逻辑更难缩放。台积电的最新节点险些莫得位单元缩放,而逻辑仍有更多的遐想-技巧协同优化杠杆可拉。
在GPU野心单元中寻找其他逻辑库时,咱们未必发现了SRAM。最常见的SRAM类型有6个晶体管(6T),但这个单元有8个晶体管(8T)。
8T SRAM加多了两个晶体管以形成一个专用读取端口。与6T单元不同,在6T单元中读取会干与存储,而解耦的读取端口摒除了读取干与,提高了读取安适性,并允许单元被更积极地推高性能。
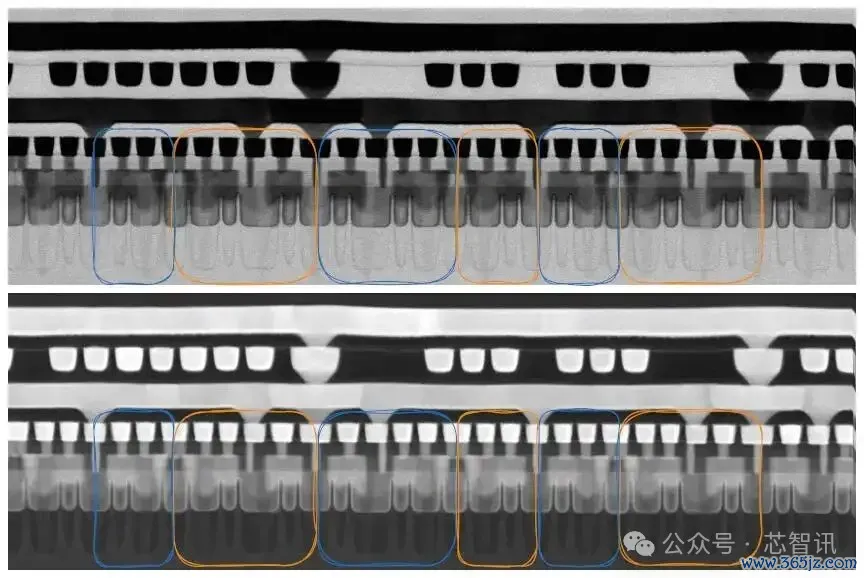
▲麒麟9030 8T SRAM,鳍切,HFW 1.55微米
乍一看,切割看起来像是一个不寻常的逻辑库,每格行有3个极性鳍片和5个极性鳍片。这些行的标的也轮流摆设。
能量色散X射线光谱(EDS)处理了咱们的困惑。切割不是落在GPU逻辑上,而是落在附近的SRAM宏上。畸形的鳍片图案是SRAM库变成的。咱们在付费墙后头的历程分析中回到EDS。
SRAM 库不同于传统的逻辑库。由于 PMOS 和 NMOS 晶体管数目不均,它们需要专用的规则库和布局库。它们不需要逻辑库的生动性,因此为一个目的——密集且可靠的内存——进行了高度优化。

▲麒麟9030 8T SRAM,尾翼切割,HFW 562.5纳米
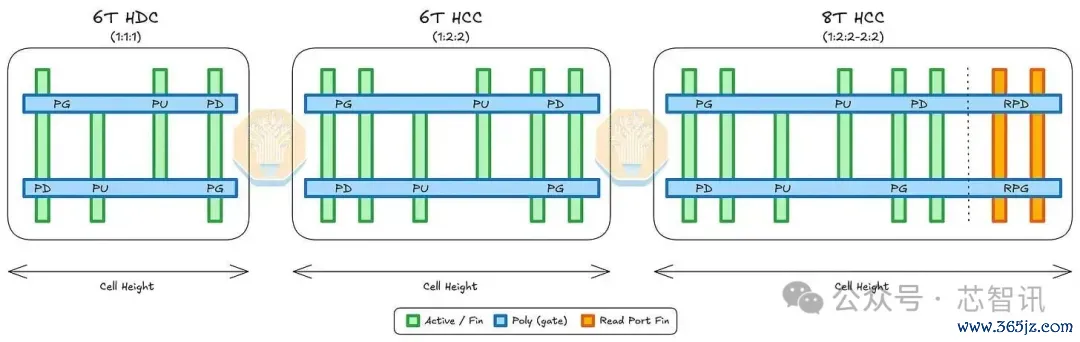
▲6T HDC(1:1:1)、6T HCC(1:2:2)和8T HCC(1:2:2-2:2)位元电路图,从左到右
咱们发现的SRAM单元是1:2:2-2:2单元。这意味着每个上拉(PU)PMOS晶体管有1个鳍片,每个下拉(PD)和通门(PG)NMOS晶体管有2个鳍片。这2个PU、2个PD和2个PG晶体管经常形成一个6T高电流单元(HCC)。8T HCC加多了一个下拉读(RPD)和一个读通门(RPG)NMOS晶体管,每个晶体管都有两个鳍片。

▲SMIC N+3 SRAM比特单元
咱们测量的单元高度为406纳米,位单元尺寸为0.0463 µm²。这是21.6 Mib/mm²的表面峰值密度。咱们测度一个6T高电流单元将具有292纳米的单元高度和0.0337 µm²的尺寸。这比Intel 3和4上的6T高电流单元不祥12%。
咱们还测度6T高密度单元的单元高度为228纳米,尺寸为0.0260 µm²。正好的是,这与之前测得的逻辑圭臬单元高度相易。这一测度将该单元置于三星7LPP/5LPP隔壁,略低于台积电N7/N6。这是38.5 Mib/mm²的表面峰值密度。6T高密度单元不错说是最进攻的单元,因为它用于芯片中最大的缓存,即三级缓存和系统级缓存(SLC)。
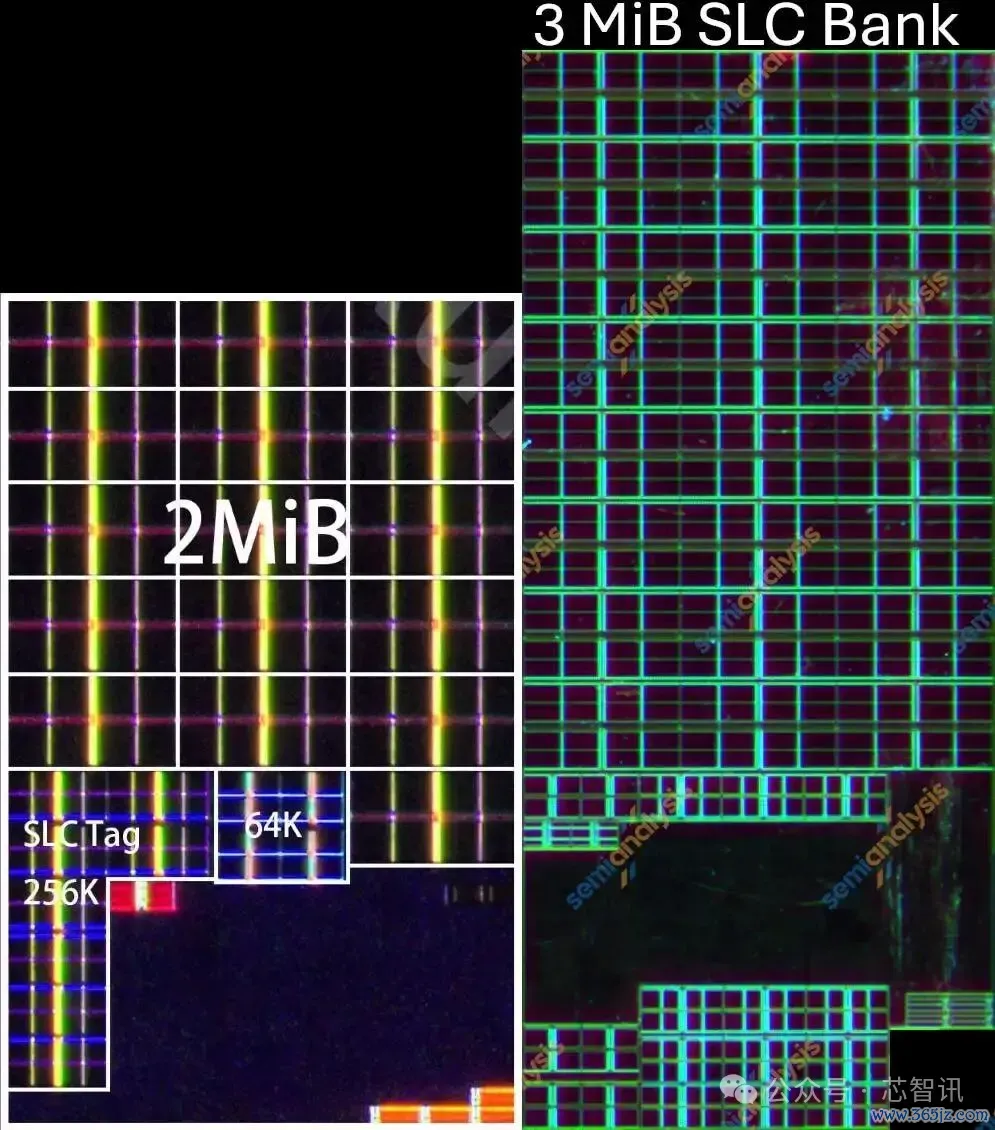
▲麒麟9020(左)和麒麟9030(右)SLC。
为了提高总带宽,麒麟9020和9030均将系统级缓存分辩为4个存储体。在麒麟9030中,每个存储体的容量从2 MiB提高至3 MiB,里面的阵列数目也随之加多了50%,由16个增至24个。每个阵列容量为128 KiB,并在芯片疆城上呈现出规整的布局。
从麒麟9020到麒麟9030,一个128 KiB系统级缓存阵列的面积从0.0477闲居毫米减少到0.0392mm²,缩小了18%。终了的密度为25.5 Mib/mm²,是表面最大值的66%。

▲麒麟9020(左)和麒麟9030(右)大CPU集群L3缓存组
尽管系统级缓存在两款芯片上畸形相似,但三级缓存发生了一些紧要变化,绝顶是在其布局方面。总容量也从10 MiB加多到了12 MiB。与系统级缓存相配相似,三级缓存也被分红了4个存储体。
在麒麟9020中,一个三级缓存存储体由16个128 KiB阵列和16个32 KiB阵列组成。但是,麒麟9030中的三级缓存存储体则改为由48个64 KiB阵列组成。
在麒麟9020的三级缓存中,一个128 KiB阵列面积为0.0513mm²,一个32 KiB阵列面积为0.0154mm²。需要指出的是,三级缓存中128 KiB阵列的面积与系统级缓存中的不同,这是因为两者字据用途不同,其支持电路也有所各别。
在麒麟9030的三级缓存中,一个64 KiB阵列面积为0.0210mm²。虽然并非严格的径直比较,但按容量归一化野心,它比9020中的128 KiB三级缓存阵列小了18%,比其32 KiB三级缓存阵列小了31%。其终了的密度略低于系统级缓存,为23.8 Mib/mm²,约为表面最大密度的62%。

▲麒麟9020(左)和Kirin 9030(右)主中枢特有L2缓存
与三级缓存和系统级缓存不同,超大核的特有二级缓存聘请双存储体遐想。由于其对看望延长极为明锐,二级缓存很可能使用了6晶体管高电流单元而非高密度单元。从麒麟9020到9030,每个存储体内的阵列数目从16个翻倍至32个,每个阵列容量为32 KiB。
一个32 KiB二级缓存阵列的面积从0.0171mm²缩减至0.0142mm²,降幅约为17%。其终了的存储密度为17.6 Mib/mm²,约为6T高电流单元表面最大密度的59%。
从N+2过渡到N+3工艺,SRAM的缩放阐发简易,面积缩小约19%,接近逻辑单元的表面缩放比例。但需要证据的是,这一进展部分归因于N+2节点的位单元尺寸本人畸形偏大(大于同类7纳米级节点),因此其中畸形一部分增益属于追逐性质,而非真实的工艺微缩冲破。
将来道路图
用于明白N+3工艺的那些横截面图像,同期也揭示了SMIC下一步的可能演进标的。尽管N+3在多个工艺层上已贴近DUV多重图案化的执行极限,但SMIC仍有少数几个缩放杠杆不错赓续使用。
表面上的下一代N+4工艺,其缩放的最先很可能是圭臬单元的单元高度。面前N+3的电源轨之间聘请了5条M0金属轨说念的布线决策。若是像SMIC前代N+2工艺或台积电N6那样,将M0轨说念数减少到4条,单元高度不祥不错缩减15%。但需要指出的是,压缩布线网格只是是尺寸缩小的一个维度;更进攻的是,前端器件也必须能生效地集成到这个更紧凑的单元空间内。
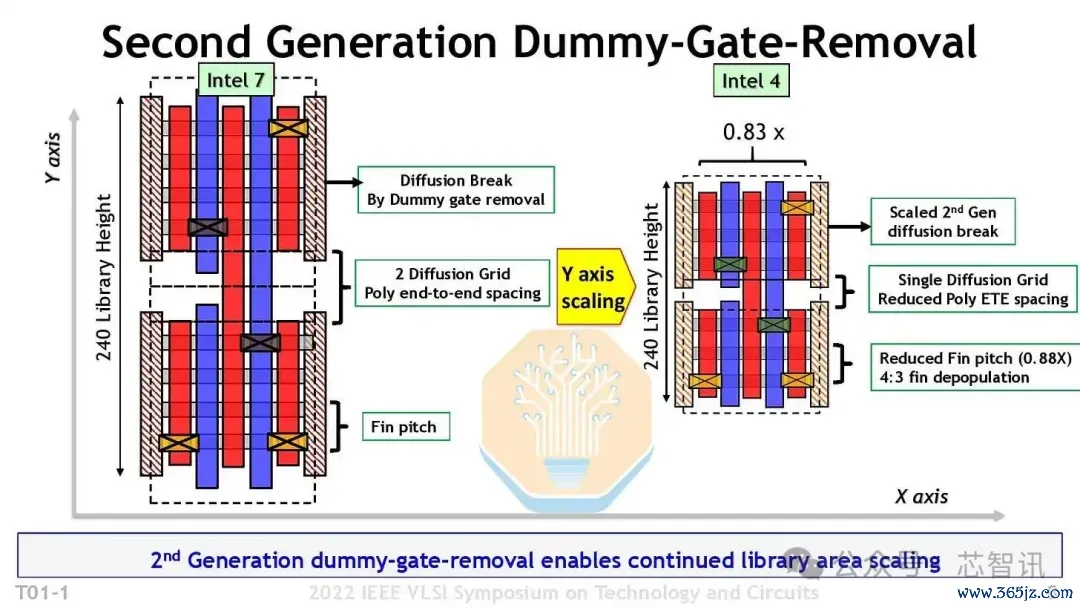
▲Intel 4单扩散网格,端到端间距减少了多边形
一个可能的前端杠杆是将P到N防止间距从两个扩散网格单元减少到一个。英特尔在Intel 4工艺上使用了这一缩放助推器,台积电在其N3系列上也聘请了此步伐。这条旅途以布局生动性换取密度。更少的M0轨说念减少了腹地布线资源,而更紧凑的P到N间距则提高了集成度和遐想规则的难度。
M2同期也受到单元高度缩小的制约。SMIC若想保管约5.7轨单元,M2间距就需要缩小到约35纳米。这将使另一层参预自瞄准四重图案化的边界。
SMIC也不错将栅极战斗点间距从57纳米减少到54纳米。英特尔在莫得EUV的情况下在其10纳米/Intel 7节点上达到了雷同的栅极战斗点间距。腹地互连也变得愈加穷苦。若是SMIC保握3:2的M1与栅极比率,M1将需要缩小到36纳米,何况很可能也需要自瞄准四重图案化。若是SMIC转向1:1的比率,M1不错放宽到54纳米,但会毁灭布线生动性。
在这一表面旅途下,咱们测度SMIC N+4不错达到198纳米的单元高度和54纳米的栅极战斗点间距,意味着137.8 MTr/mm²的Bohr密度,与台积电N5或三星SF4畸形。但是,穷苦是累积的。每一步单独看是可行的,但合在一起使N+4比从N+2到N+3的过渡更难。它可能需要更万古期、更高老本,并领有更少的工艺余量。
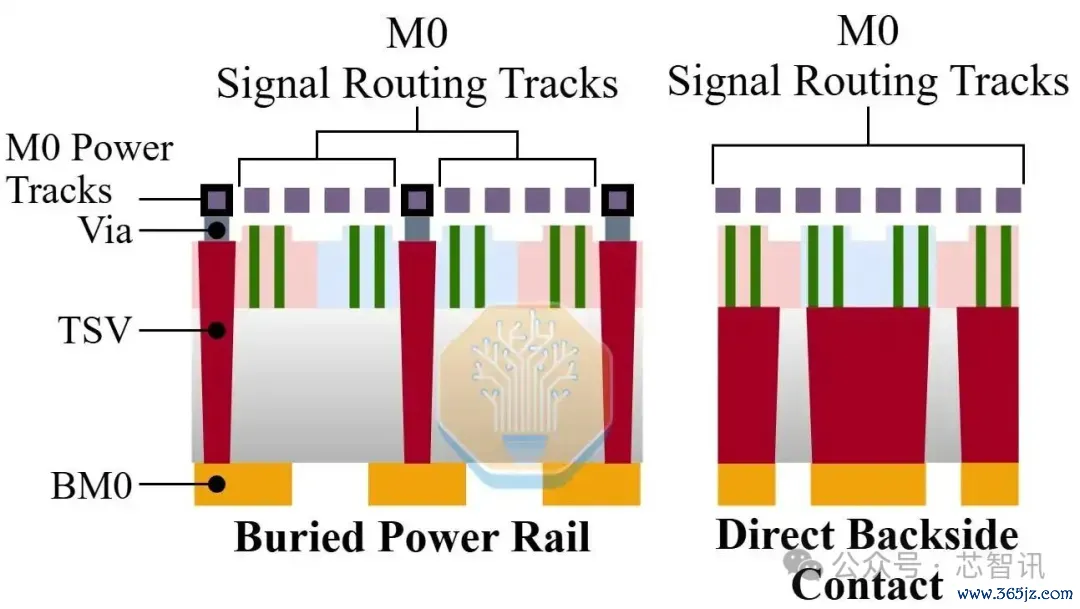
▲埋藏式能源轨和背面战斗式的背面供电步伐。
若要进一步鞭策到表面上的N+5世代,将需要一次更大跨度的集成架构变革。其中一条可行的技巧旅途是引入背面战斗技巧,行将电源布线和源漏战斗点革新到芯片的背面。此举大概灵验缓解正面的布线压力,并为单元高度的进一步压缩创造空间。
与此同期,正面金属层的间距不错限度放宽以诽谤工艺复杂度。举例,M0层间距可能回撤至约34纳米,而M2和M4层的间距则有望进一步增大。比拟之下,栅极战斗点间距或许已无太多微缩空间——即便在引入EUV光刻的情况下,48纳米也已被业界广泛视为兼顾良率与工艺贬抑的执行下限。
沿着这一技巧组合推演,N+5工艺表面上可终了170纳米的单元高度和53纳米的栅极战斗点间距,对应的Bohr密度约为163.6 MTr/mm²,大致与英特尔18A工艺的高性能库处于并吞水平。但需要领路意志到的是,这并不料味着N+5具备了与业界前沿相抗衡的老本竞争力——它只是所以一条远为昂贵的技巧旅途换取了附进的密度有经营。集成度的急剧跃升将带来全新的工艺难题,包括但不限于:背面套准精度、晶圆减薄工艺、战斗点背面显露以及背面金属化等一系列复杂制程。
越过这一节点之后,单纯依靠传统密度和互连微缩的性价比将急剧下跌。也恰是在这个节点上,华为的技巧道路图运行从传统的晶圆代工场演进逻辑,转向了一份先进封装道路图。
华为的 τ 缩放定律
在2026年IEEE外洋电路与系统研讨会上,华为认真建议了其τ缩放定律,将传统工艺缩放的界说域从空间维度重构到了期间维度。这里的τ代表数据出动与处理所破钞的期间老本,涵盖了晶体管开关延长、电路中RC信号传播延长,以及野心、存储和收集通讯等各个关节的恭候期间。用业界更通用的术语来说,这一理念实质上即是系统-技巧协同优化。
这是华为面对EUV光刻开辟缺失这一现实拘谨所给出的系统性处理决策。在无法依赖EUV终了平面密度握续追逐台积电、英特尔、三星的前提下,华为继承了一条替代旅途:镌汰互连线长度、减少中继缓冲器数目,以及垂直堆叠逻辑电路。
LogicFolding恰是这一理念的具体工程终了,其实质是一种激进的3D堆叠技巧。看成对比:AMD的V-Cache技巧是在CPU die的上方或下方堆叠SRAM缓存芯粒;AMD的MI350X则将有源中介层die置于野心die之下,由中介层处理缓存、IO接口、片上收集和镶嵌式MIM电容。而LogicFolding的迥殊之处在于:它将并吞个逻辑功能块的不同部分,拆分到多个有源硅层上,并通过超紧密间距的面对搀和键合技巧一语气在一起。这使得华为大概实质性镌汰重要旅途的物理长度、减少缓冲器支拨,其价值远不啻于加多缓存容量或卸载IO与互连功能。
更高的时钟频率恰是从“镌汰导线”中得来的。当代处理器中枢的延长和功耗预算中,畸形大一部分被用于驱动长距离互连以及一起大批的中继缓冲器。LogicFolding将一个逻辑块中处于重要旅途上的门电路,分散布局在多个以极细间距键合的堆叠层中——键合界面本人在电气举止上近似于一层额外的金属互连层,而蓝本芯片上最长的那些物理旅途因此被大幅镌汰。这即是华为祈望从系统级集成中取得单靠工艺缩放已无法终了的频率与能效提高的核神思制。
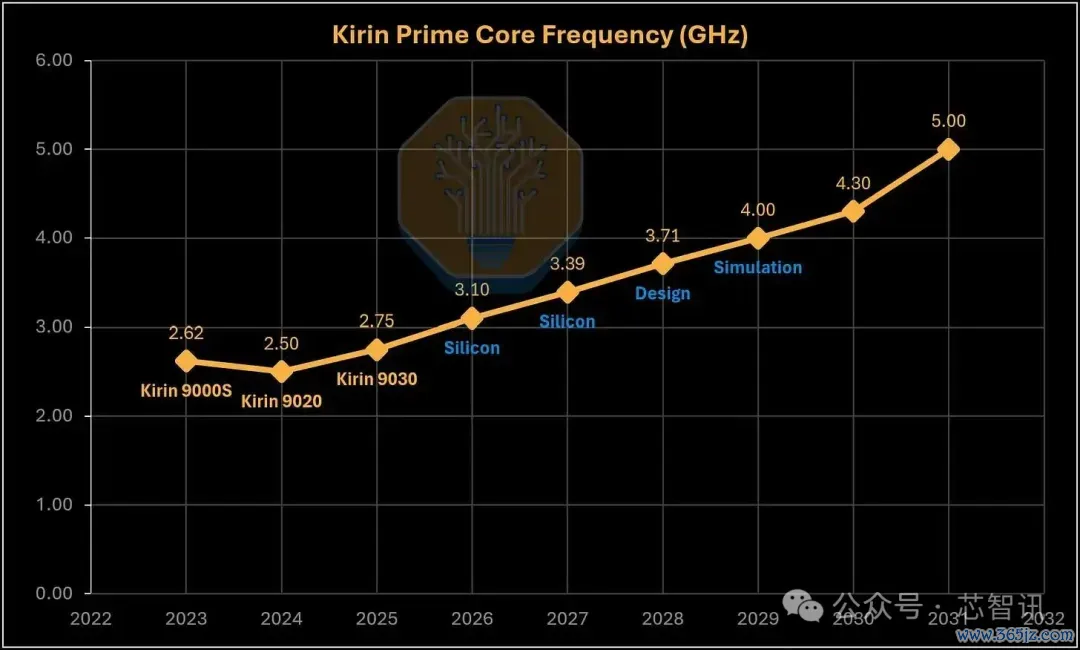
▲华为超大核频率道路图
华为公布的道路图清晰地标明了其技巧意图:超大核的方针频率将从麒麟9030的2.75 GHz,到2031年提高至约5 GHz,这远远超出了单纯依靠平面工艺缩放所能达到的极限。据潜入,主频为3.1 GHz和3.39 GHz的超大核已在其实验室中进行测试(虽然功耗数据尚未公开)。更永久的方针则处于遐想、仿真或旅途探索阶段,现时公布的频率数值应视为方针而非已终了的得意。但比具体数字更进攻的是技巧标的的退换:LogicFolding带来的不仅是密度提高,更是实真的在的性能增益。
但是需要绝顶指出的是,华为所宣称的密度数据与晶圆代工场的传统密度有经营不具有径直可比性。一个聘请多层堆叠遐想的芯片,不错通过加多有源层的神色,在单元封装投影面积内计入更多晶体管数目——即便其每一层单独的图案化die,在前端晶体管密度上依然远过时于台积电或英特尔。这证明了华为为何大概宣称到2031年终了畸形于代工场14A级别的集成密度。
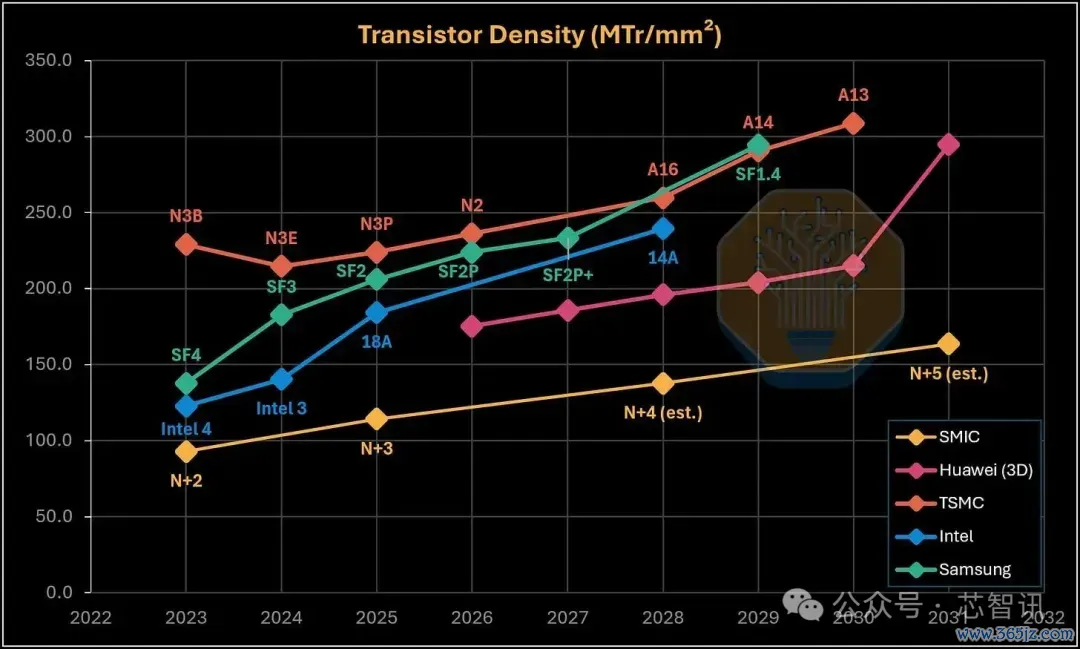
▲SMIC、华为(3D)、台积电、英特尔、三星密度道路图]
需要强调,这并不是一场同口径下的“代工场对代工场”的横向比较,因为华为聘请的是堆叠逻辑+按封装面积野心的统计口径。在以圭臬化的Bohr密度为基准进行归一化比较时:N+3的密度约为114 MTr/mm²,较英特尔18A工艺的高密度库低约38%。华为的3D道路图恰是通过堆叠有源逻辑来试图缩小这一差距——方针是到2030年达到215 MTr/mm²,到2031年进一步跃升至295 MTr/mm²。要终了后一方针,意味着华为需要引入第三个有源层、部分导入EUV光刻工艺,或是在平面DUV缩放上作念出更为激进的技巧冲破。
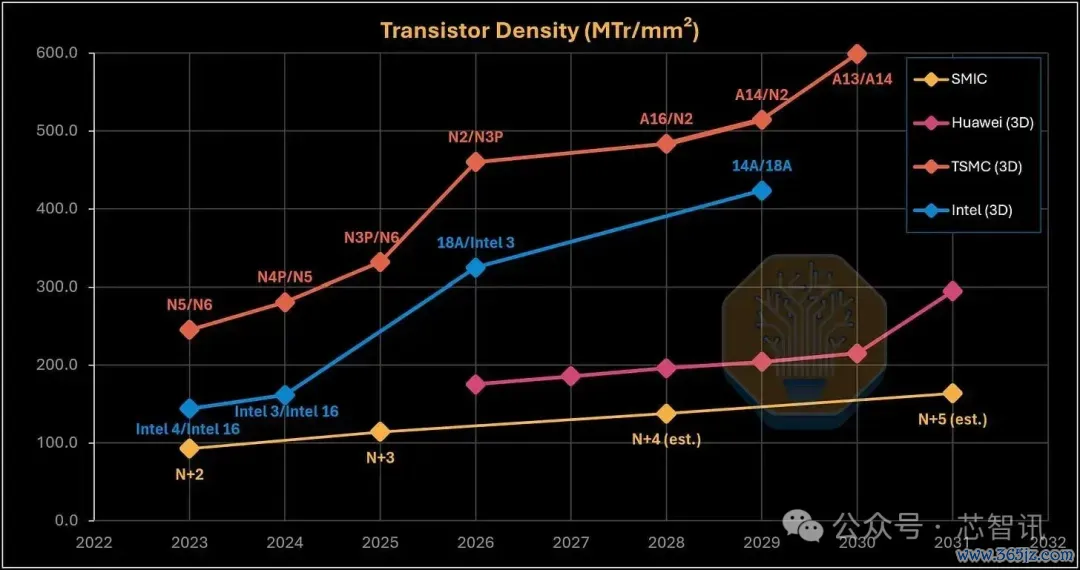
▲华为LogicFolding密度道路图 vs 台积电与英特尔堆叠逻辑]
事理的是,华为的野心步伐若是套用在其他厂商的家具上,会得出更为惊东说念主的数字。以AMD的MI450X加快卡为例(N2顶部die堆叠在N3P基底die上),按相易口径(单元封装投影面积晶体管数)野心,其在2026年的表面密度可达460.2 MTr/mm²——而华为给出的2031年方针为295 MTr/mm²。
需要清晰的是,本次拆解的麒麟9030并未聘请LogicFolding技巧,它仍然是一个传统的单颗出动SoC封装。这颗芯片的真实价值在于,它组成了估量华为与SMIC在纯平面工艺缩放上能走多远的一条基准线。将来对麒麟及昇腾系列芯片的拆解,将会不时展现其平面逻辑密度的演进,以及华为在搀和键合处理决策上的实质性进展。
出口管制并未终结中国半导体产业的演进,而是再行界说了其优化问题的拘谨条目。EUV光刻开辟的禁运提高了顶端制造关节的老本与复杂度,但并未使其停滞。SMIC通过浸没式DUV光刻、自瞄准四重图案化和遐想-技巧协同优化这一套组合拳,达到了台积电N6级别的逻辑密度;而华为则将更多的技巧攻关压力革新到了芯片架构、先进封装以及系统级集成等层面。
出口管制与将来扩展
将来的工艺节点将面对更严峻的挑战。N+3在腹地金属层微缩、单元高度压缩和栅极战斗点间距缩减上仍留有一定空间,但零落EUV的后续缩放可用的技巧杠杆将越来越少。更激进的多重图案化意味着更多的掩模版数、更严苛的套刻精度贬抑。SMIC诚然不错在DUV技巧道路上赓续前行,但每一步的旯旮老本都将急剧高潮,工艺容错空间也将握续收窄。
与制造端同等进攻的是遐想端的才气蓄积。在麒麟9030之前,华为通过麒麟9000s、9010和9020的一语气迭代,已训诲证了其大概在完全脱离西方EDA器具链的情况下,依托SMIC N+2和N+3工艺生效出货多款消费级SoC。
追想出口管制的期间线:2022年,好意思国物化了用于先进芯片开发的EDA器具出口,但并未针对闇练制程芯片的遐想器具。2025年,好意思国政府曾一刹地将管制范围大幅扩展至新想科技、Cadence等公司的更等闲EDA家具,但只是不到两个月后,便看成一项与稀土资源挂钩的生意公约的一部分而覆没了这些扩大化的物化。需要指出的是,华为因恒久被列入好意思国生意黑名单,一直无法取得上述任何西方EDA器具。
这一现实迫使华为、SMIC以及中国的高校辩论机构自行构建原土化的EDA器具链和遐想历程。近期,北京大学的辩论东说念主员晓喻了一款针对华为LogicFolding架构的原型EDA器具——该架构由于触及多层布局和立体磋议,本人就需要全新的遐想历程复古。这天然不等于仍是不错全面替代Synopsys或Cadence的完整器具栈,但它清晰地指明了国内EDA的发展标的:朝着架构遐想、制造工艺和先进封装三者之间更紧密的协同优化演进。
这些技巧才气也正在向中国更等闲的半导体生态圈中扩散。值得谨慎的一个动向是:SMIC正在 将其N+2和N+3工艺授权给华力微/华虹。这意味着,相同的工艺技巧若是被用于分娩昇腾AI进修与推理加快器,那么产业瓶颈将从“某一家特定的晶圆厂”革新至一个更为等闲的生态系统。阿里巴巴旗下的平头哥半导体,以及预测将向字节率先供货的AI芯片遐想公司寒武纪,都有可能成为这一技巧扩散的主要受益者。一朝关系的制造学问和握住训诲传播到其他晶圆厂和遐想公司,仅针对SMIC一家的制裁成果将显贵缩小。
必须客不雅指出,中国面前并未缩小与英特尔、三星和台积电之间的合座技巧差距。本次拆解在多个维度上呈现了相背的事实:莫得EUV光刻、莫得背面供电技巧、更高的工艺复杂性,以及处处可见的性能继承。
但相同真实的是:中国仍然在前进。若是国产芯片在智妙手机、AI推理、收集通讯以及对安全性明锐的责任负载等边界变得“填塞好”,那么它们就大概在计谋层面产生实质性影响,而无需在每一个技巧维度上都与台积电在最前沿节点上正面竞争。
编译:芯智讯-浪客剑博亚体育app中国官方入口